-

行业白皮书深度剖析cdn全球份额分布与地区竞争格局
2026/6/2 -

风险应对策略国内高防免备案cdn遭遇攻击时的快速响应流程
2026/6/1 -

实施cdn星河加速后提升页面打开速度的实操指南
2026/5/3 -

成本与运维对比帮助企业选择cdn高防和cdn云盾的平衡点
2026/6/24 -

实施前须知高防CDN行吗合同条款与服务等级说明
2026/5/11 -

移动端优化实操教你cdn怎么下载并实现H5加速
2026/4/7
长期防护策略构建以降低CDN全球节点社交崩盘发生概率
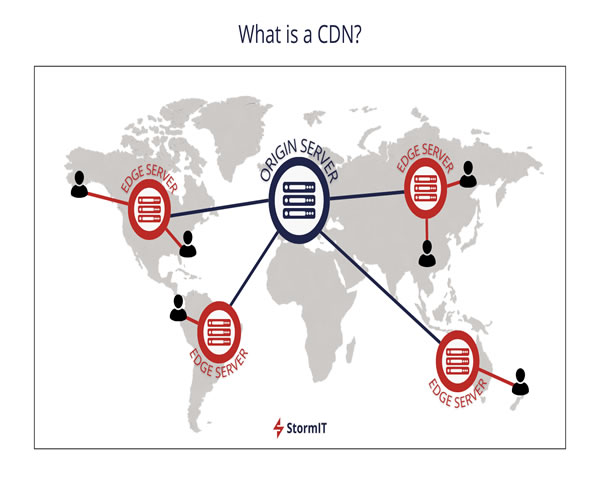
长期防护策略构建以降低CDN全球节点社交崩盘发生概率 — 三大精华
1. 精华一:通过多CDN + Anycast 与主动流量调度,打造跨区域容灾骨干,减少单点节点崩溃引发的连锁效应。
2. 精华二:以< b>观测与告警为核心,结合AI异常检测与自动化伸缩,做到“秒级识别、秒级缓解”,将社交崩盘爆发窗口压缩到最短。
3. 精华三:推行“防御即代码、演练即常态”的运维文化,定期进行DDoS攻防、混沌工程与流量风暴演练,确保长期防护策略落地为可验证的能力。
任何以社交传播为核心的互联网产品都可能遭遇瞬时流量洪峰,也就是我们常说的社交崩盘——用户行为、话题走红或恶意放大都能在分钟级产生数十倍流量。单靠临时加车或者单一供应商的弹性很难持久抵抗这种冲击,因此必须构建一套系统性的、经得起实战检验的长期防护策略,专注于提高CDN全球节点的整体稳定性与抗风险能力。
首先,从网络与架构层面必须实现多重冗余。采用Anycast对外发布,提高路由级别的快速就近引导;同时与多个CDN供应商建立互备关系,通过智能流量调度平台在遇到局部异常时实现秒级切换。增强的策略还包括边缘缓存策略优化(合理TTL、缓存预热、原点护盾)、源站退避与拥塞控制,确保某一区域节点压力骤增时不会直接打穿后端服务。
在安全面,必须把DDoS防护和应用层防御并列为长期投资。部署多层防护:网络层大流量清洗、边缘缓存的吸收、WAF与行为风控防止Layer7滥用、以及基于IP信誉和设备指纹的机器人识别。结合带宽池、流量清洗中心与合作厂商的黑洞策略,形成“吸收-清洗-回落”的闭环。
技术细节上,建议实施以下关键点:1) Origin Shield或中间缓存层减少源站负载;2) 细化缓存策略,按内容类型(静态、动态、API)设置不同缓存粒度;3) 使用HTTP缓存头与变体缓存(Vary)避免缓存污染;4) 对于热点接口采用局部缓存、短时异步队列或渐进式降级,确保核心路径稳定。
观测与告警是长期防护的中枢神经。必须建设覆盖全链路的指标体系:缓存命中率、边缘带宽利用率、P95/P99延迟、错误率、并发连接数和SYN速率等都要入表。结合日志、追踪与采样,使用基线+机器学习的异常检测模型实现早期预警。告警策略要分级并具备自动化响应能力——如触发< b>自动伸缩、切换CDN供应商或调整流量策略。
演练与验证不可或缺。每月例行的流量演练、季度的混沌工程和年度的全面攻防演习,都是把长期防护策略从文档转为能力的必要流程。演练要覆盖从流量入口、路由决策、CDN交换、到后端数据库与缓存,确保在各类故障模式下都有明确的失效路径与恢复脚本。
在治理与组织方面,推行“防护即代码”理念,把防护配置纳入版本管理和CI/CD流水线,所有策略变更通过审计与回滚保障。同时制定清晰的SLO、SLA和复盘机制。技术委员会定期审核供应商表现、成本效率与合规性,确保长期投入有回报。
针对社交场景特有的传播特性,应采取业务层面的抑制措施:对热点内容做逐级曝光限制、对带有病毒传播特征的操作引入人机验证、对API进行细粒度的速率限制并使用令牌桶或漏桶算法做熔断。若是消息推送或评论流等高频写操作,考虑使用消息队列打平突发写入峰值,做到“削峰填谷”。
在多云与多供应商策略下,做好数据一致性与配置同步。采用边缘配置中心与统一监控面板,确保不同全球节点在策略下发与度量采集上的一致性。同时定期进行故障注入验证多CDN切换与全量回流场景,避免切换时出现配置错配导致的新问题。
成本控制方面,长期防护不等于无限扩容。通过流量分层定价、缓存命中率优化和智能路由降低实际带宽成本。把防护效果量化成降低的事故成本(恢复时间、用户流失、品牌损失),以数据支持长期投入决策。
合规与信任建设也是EEAT中不可忽视的一环。确保所有安全与监测措施满足当地法律与隐私要求(如GDPR、CCPA等),并定期接受第三方安全评估与穿透测试,以增强组织与用户的信任。
最后,指标化与持续改进:将防护能力拆解为可量化的KPI(如节点可用率、平均恢复时间MTTR、缓存命中率提升百分比、攻击检测精度等),每一轮演练后进行复盘并把改进项纳入下一季度计划。长期来说,稳健的长期防护策略是技术、流程与文化的协同产物。
总结:面对由社交传播带来的流量炸裂风险,单一靠弹性扩容或临时应急已难以立足。采用多CDN + Anycast架构、强化DDoS防护与应用层风控、把观测与自动化作为防护中枢,并通过持续演练与治理把这些能力固化为常态,才能真正将社交崩盘的发生概率降到最低。现在就把这些策略拆成可执行的里程碑,开始第一轮演练,别等下一个新闻事件来临时才慌张应对。
若需一份可执行的30天实施清单与演练脚本(含观测仪表盘模板与告警策略),可联系专业团队进行定制化交付,确保策略在真实流量下被检验并迭代。