-

迁移案例海外网站cdn加速什么意思啊旧站点如何平滑切换流程
2026/7/9 -

开发者问答汇总阿里云cdn支持海外吗的常见技术问题
2026/6/27 -

海外视频cdn租用 QoE质量评估指标与监控实施方法
2026/3/27 -

cdn如何加速动态请求时数据一致性和安全性的处理方法
2026/5/6 -

遇到墙问题时海外站点被墙可以用cdn吗 各种方案的可行性评估
2026/3/31 -

运维手册教你测试阿里云cdn支持海外吗的网络连通性
2026/6/28
游戏运维视角解析游戏服务器部署cdn 的故障排查与恢复方案
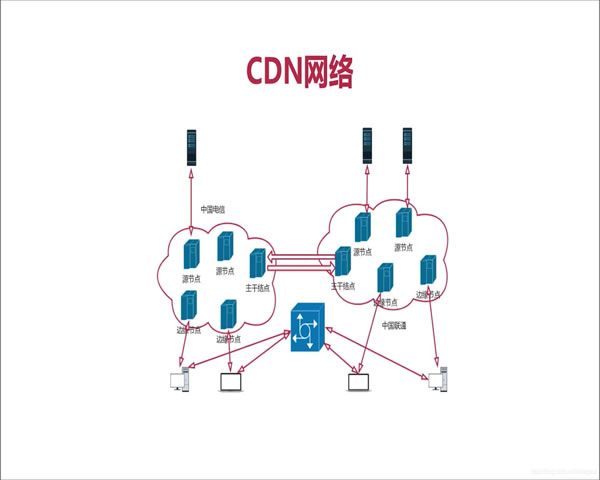
本文从一线运维实践出发,概述在为游戏服务器接入CDN后可能引发的常见问题、快速定位思路与可执行的故障排查与恢复方案,并给出优先级判断与防范建议,帮助运维团队在保证玩家体验的前提下高效恢复服务。
哪个环节最容易出现问题?
在将CDN用于游戏场景时,最脆弱的环节通常是:1)DNS解析与流量调度导致的访问偏差;2)边缘节点与源站之间的网络链路;3)缓存策略引发的业务数据不一致;4)TLS/证书和负载均衡器配置错误。运维应优先核查这些环节,结合监控数据判断影响范围(是区域性还是全局)。
哪里该先排查以缩短恢复时间?
排查顺序建议遵循“从外到内、从快速可验证项到深层依赖”的原则:首先检查DNS与CDN控制台的健康状态与流量告警;其次验证边缘节点响应(curl/tracepath/ttl等)和HTTP状态码;再查看源站连接与后端服务健康(应用日志、数据库连接);最后核验缓存命中率与配置是否被误改。优先排查可以把恢复时间降到最低。
为什么会出现缓存污染或数据不一致?
缓存污染常因错误的缓存策略或业务头部忽略导致,例如未区分玩家会话、使用了错误的Cache-Control或Vary头,或边缘与源站时间窗不同步。另一个常见原因是部署策略(比如灰度发布、回滚)未在CDN上同步触发,导致新旧版本混合访问。解决需要校验缓存规则并强制刷新受影响节点。
怎么快速确认是网络链路还是应用层问题?
快速区分可以通过三步:1)从不同地域和不同运营商发起简单连通性测试(ping/traceroute)判断链路丢包与时延;2)用curl/openssl s_client检查TLS握手和HTTP响应头,确认是否为应用返回的错误码或CDN生成的错误页面;3)查看源站访问日志与边缘请求日志对比,若边缘未到达源站,则偏向网络或CDN配置问题,反之为应用或后端故障。
如何制定分级的恢复方案?
根据影响范围和业务优先级制定恢复策略:紧急(全服或关键区域宕机)——立即回滚到稳定发布并触发CDN全局缓存失效与DNS回退;高优先(部分区域或延迟)——选择局部回滚、调整流量切分和边缘规则;低优先(单功能异常)——限流、降级或临时关闭该功能并安排补丁。每一步应记录变更并保持可回滚的操作手册。
多少时间内能完成恢复?
恢复时间取决于问题类型:DNS回退通常需要TTL的传播时间(几秒到几小时);CDN缓存刷新在多数厂商可在数十秒到数分钟生效,但全网刷新可能更长;应用回滚和发布可在几十分钟到数小时完成,数据库修复或数据一致性问题可能需要更长时间并伴随数据回放。为缩短RTO,应预先准备好回滚包与自动化脚本。
怎么保证后续不再复发?
防范措施包括:1)在变更前进行流量回放与灰度验证,测试CDN配置与源站交互;2)完善监控和告警,覆盖边缘关键指标(命中率、错误码分布、边缘响应时延)与回源流量异常;3)建立CDN配置的变更审批与回滚流程,使用基础镜像与配置模板管理;4)定期演练灾备方案并模拟DNS/边缘故障。
如何在运维工具链中实现自动化诊断与恢复?
建议将常用的诊断步骤脚本化并接入告警平台:自动化收集边缘与源站日志、触发trace路由、比对错误码分布并在阈值触发时执行预定义恢复动作(如切换流量、刷新缓存或回滚发布)。同时把运维经验转化为Runbook和Playbook,结合CI/CD实现一键回滚与变更审批,降低人为误操作风险。